
One of the highlights of the syslog-ng 4.3.0 release is parallelize(). Normally, syslog-ng processes incoming messages from a TCP connection in a single thread. While this works fine with many connections, it is a bottleneck when using a single or very few high-traffic connections. Using parallelize() allows syslog-ng to process log messages from a single high-traffic TCP connection in multiple threads, thus increasing processing performance on multi-core machines.
As you will see, parallelize() helps when you have a single high-traffic TCP connection. In this case parallelize() distributes incoming messages to multiple threads, so resources are better utilized. However, when using many TCP connections, parallelize() only gives an extra overhead. Likewise, you don’t need to use parallelize() if you have a single low-traffic connection, as a single thread can handle the messages without being a bottleneck in that case.
Before you begin
Using parallelize() requires modifications to the ivykis library, used by syslog-ng. While the version bundled with syslog-ng contains these modifications, the upstream version of ivykis does not. This means that parallelize() is unavailable right now on most platforms.
Currently you can get parallelize() by three means:
-
Use my unofficial openSUSE / SLES 4.3.0 packages, or official openSUSE Tumbleweed package, as these use the bundled ivykis version.
-
Use the Axoflow container images.
-
Compile ivykis and syslog-ng (or syslog-ng with the bundled ivykis) yourself.
If you compile syslog-ng yourself, you have two possibilities. You can either compile syslog-ng using the bundled ivykis, or you can compile ivykis separately. In the second case, you need the patch from https://github.com/buytenh/ivykis/pull/25, and you need to compile ivykis first, then compile syslog-ng after that. Syslog-ng detects the modified ivykis at compile time, so simply recompiling ivykis is not enough if you use system ivykis instead of the bundled version.
I hope to figure out a solution for my Fedora / RHEL packages (most likely adding a patched ivykis to my unofficial repo). I also try to find a solution for FreeBSD ports.
Configuration
Once your syslog-ng supports parallelize(), you can enable it by adding it to a log path where it is useful: a log path which receives a single high-traffic TCP connection. Here is an example configuration from the git commit message:
log {
source {
tcp(
port(2000)
log-iw-size(10M) max-connections(10) log-fetch-limit(100000)
);
};
parallelize(partitions(4));
# from this part on, messages are processed in parallel even if
# messages are originally coming from a single connection
parser { ... };
destination { ... };
};
As you can see, this option is right after the source in the log path. The partitions() parameter configures the number of threads to use.
Testing
You can use loggen to generate some load on your tcp() sources and check the effect of parallelize() in your environment. The most important loggen parameter in this case is “--active-connections=”, which configures how many connections loggen opens towards syslog-ng. You also need to change the “-r” option (rate) to a high number, as the default 1000 messages a second is not enough to see the difference.
Results
I did my own tests on an AMD 5800X machine running openSUSE Leap 15.5, syslog-ng 4.3.0 from my unofficial repositories, and the sngbench scripts. You can learn more about sngbench, a shell script to performance test your syslog-ng at https://www.syslog-ng.com/community/b/blog/posts/introducing-sngbench-a-shell-script-to-performance-test-your-syslog-ng.
By default, sngbench uses two syslog-ng configurations with various numbers of TCP clients. In the following graph, “m” means performance-optimized and “d” means a lot more complex distro configuration. The numbers behind the letters mark the number of parallel TCP connections and the number of loggen clients (if there are more than one).
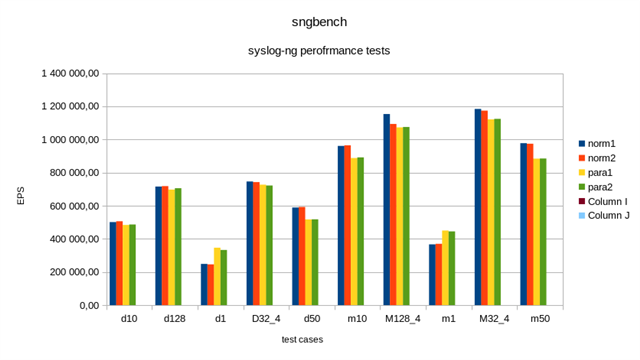
First, I ran the original configurations from sngbench, marked with “norm”, then repeated with parallelize() enabled, marked with “para”. Sngbench was run twice for each scenario (and each sngbench run repeats the tests three times).
As you can see, when there is only a single TCP connection, parallelize() provides a 40-50% performance increase. However, with multiple clients, there is a slight performance degradation. It is most visible around 50 TCP connections in my case.
What is next?
If you have a scenario where you have a single high-traffic TCP log source, you should give parallelize() a try.
-
If you have questions or comments related to syslog-ng, do not hesitate to contact us. You can reach us by email or even chat with us. For a list of possibilities, check our GitHub page under the “Community” section at https://github.com/syslog-ng/syslog-ng. On Twitter, I am available as @PCzanik, on Mastodon as @Pczanik@fosstodon.org.