- Video Gallery
- Using syslog-ng with Google Pub/Sub
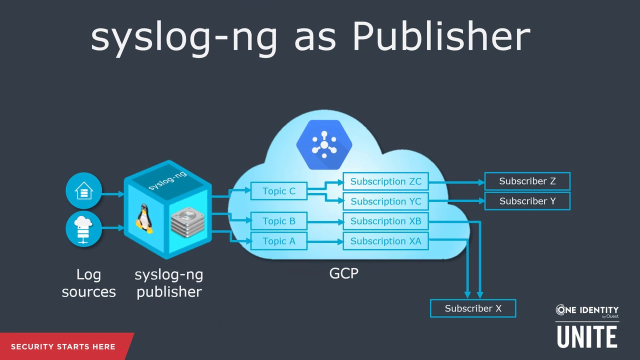
Using syslog-ng with Google Pub/Sub
 25:56
25:56
Learn how to use syslog-ng PE to send and receive log messages using the GCP Pub/Sub asynchronous messaging system
Show Transcript
Hide Transcript
My name is Craig Finn, and I'm a systems engineer with One Identity, specializing in syslog-ng. And in this session, I'm going to describe how you can utilize syslog-ng with the Google Cloud Pub/Sub application.
So syslog-ng, as you probably well know, is an application that allows you to centrally collect, process, and securely store log messages. It's an application that is suitable for being your enterprise log management layer. So you only need one application that gives you high performance, high reliability, and it's very feature rich and easy to use. But that's the only tool that you will, in fact, need for log collection.
And what it does, is not only collects, processes, and stores logs from all of the devices and applications in your enterprise, it can also send those messages, or subsets of those messages, to other applications-- other security tools, SIEM tools, databases-- many, many other applications that you might want to use to analyze and process the logs in other ways. And it's very often used to optimize SIEM ingestion. So in other words, we take care of ingesting logs, doing some processing, categorization, and filtering, then send them on down to your SIEM tool, which can then run in a much more efficient manner, because it doesn't have to do what it's run not really optimized for. It can specialize on what it's designed to do, which is analyze and provide actionable intelligence on a data that syslog-ng is providing to it.
And syslog-ng itself-- and in particular, I'm talking about syslog-ng premium edition, which is the edition of syslog-ng that comes with commercial support from One Identity. You may be familiar with the open source version of syslog-ng. Premium edition is very much in that same vein, but it has many enhancements, and, of course, it obviously is supported by One Identity-- with up to 24 by 7 support, and in fact, enhanced support levels even above that. But syslog-ng is-- essentially, it's a Linux application, and you can run it in one of three modes-- server mode, which is the most common. That's where you would ingest logs, process, and store them. but you can also deploy it in what we call relay mode and client mode.
I'll have more to say about relay mode in a couple of slides. Client mode is a means by which you can install it on a Linux VM or other instance and use it to replace the native syslog daemon that may have come with that distribution that you're using. So it's not required, you don't have to have our code running on an endpoint to collect logs from it, but it gives you some additional capabilities when you do deploy syslog-ng in the client.
And you know, I promise to talk about relays. Relays have a couple of very important uses. One of them is to enhance-- greatly enhance-- the reliability of log collection from devices or applications that may be constrained for one reason or another to utilize UDP as the transport mechanism. And UDP is, of course, it's very efficient. It was the network protocol that was designed into the syslog protocol to begin with, back in the late 80s. But it does have one problem.
UDP is, by design, an unreliable protocol. It's really fire and forget. It's when a sender sends a datagram via UDP, he sends it, it gets into the network, neither the sender nor the receiver is aware of any problems with that datagram. It could get dropped somewhere along the network at a router interface, and no one's any the wiser. And that could be a problem, because you're depending on your log analysis tools and security tools to really be aware of what's happening in your network. These UDP datagrams, they may be carrying essential information, and that needs to be attended to immediately. And if they get dropped, that's obviously not available to you.
So what you can do is, in cases where you have UDP sources that maybe have to traverse a complex network with a lot of network hops, and they're using UDP, you can locate a syslog-ng relay close to those sources-- say it maybe it's in a remote site. The relay-- since it's close to the sources, from a network topology sense-- will have a high chance that the UDP packets will make it intact to the relay. The relay then can resend those messages using a more reliable protocol-- like TCP/IP.
It can also help you if you have extremely large organizations, with perhaps multi tens of thousands of simultaneous TCP connections. In that case, you can have a TC-- relay multiplex that multiple tens of thousands of TCP connections down to one connection to your server at your central or primary data center. So they're very useful in very large environments.
And of course, you can integrate syslog-ng with other parts of your network infrastructure. So you can also have syslog-ng instances running behind a network load balancer. And that could provide, obviously, load balancing and scaling, and also reliability. The load balancer could have health checks, and if it determines that one of the servers is down, it could make sure that all the messages get sent to the surviving instance.
Now I'm going to describe syslog-ng in a little more detail here. So this block diagram shows the essential part of syslog-ng, which is that it's a log or message processing pipeline. In fact, it's an oversimplification in some ways, because it's not just one pipeline, but it's many, many parallel pipelines, many log processing paths, and then many parallel network destinations. And all of these paths, sources, and destinations are multi-threaded for performance.
But in essence, what happens is syslog-ng will be collecting messages, either from the network, and it will do that using any protocol-- any network protocol, any syslog protocol, from any device, from any application. It will also collect log messages